
Nvidia is under scrutiny following leaked documents that reveal its extensive practice of scraping videos from platforms like YouTube and Netflix to train its upcoming video foundational model. This ambitious project, internally known as the “Cosmos” project, has raised significant concerns regarding copyright laws, ethics, and the future of AI training. With Nvidia’s Video Scraping removed from public platforms, these revelations have intensified the debate around responsible AI development.
Table of Content
- Nvidia’s Ambitious “Cosmos” Project
- What is Video Scraping?
- Nvidia’s Use of yt-dlp Tool
- The Scale of Nvidia’s Data Collection
- Applications of the Cosmos Project
- Employee Concerns and Management’s Response
- Copyright Issues and Fair Use Argument
- Google’s Response to Nvidia’s Practices
- Netflix’s Stance on the Matter
- Legal Implications and Potential Consequences
- Public Reaction and Media Coverage
- Ethical Considerations in AI Training
- Future of AI Video Training Models
- FAQ
Nvidia’s Ambitious “Cosmos” Project

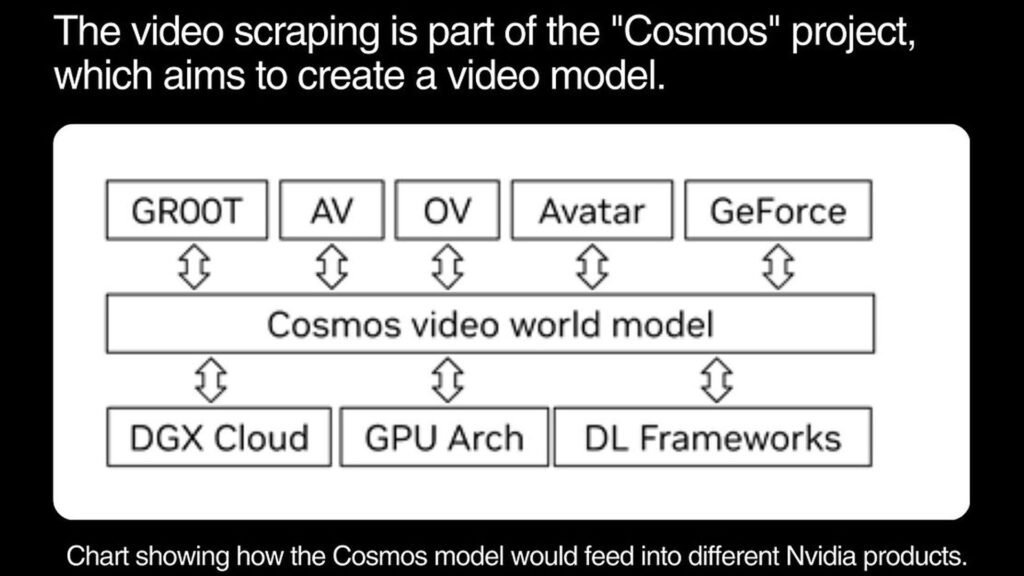
Nvidia’s “Cosmos” project aims to create a powerful video foundation model capable of simulating light transport, physics, and intelligence for various applications. This project represents Nvidia’s commitment to advancing AI technology, pushing the boundaries of what’s possible with video content analysis and simulation. With Nvidia’s Video Scraping removed, the Cosmos project signifies a new era of innovation and precision in video technology.
What is Video Scraping?
Nvidia has removed its video scraping practice, which involved extracting video content from various online platforms without the explicit permission of content creators. This practice, used to train AI models by providing vast amounts of data, faced removal due to ethical and legal concerns.
Nvidia’s Use of yt-dlp Tool

To carry out this massive data collection, Nvidia reportedly uses an open-source tool called yt-dlp. This tool allows downloading a lot of video content from platforms like YouTube and Netflix. This content is used to train AI models. However, Nvidia’s video scraping efforts have been curtailed. ‘Nvidia’s Video Scraping’ has been removed from their official practices.
The Scale of Nvidia’s Data Collection

Nvidia’s Video Scraping efforts are staggering. The company reportedly downloads 80 years’ worth of videos daily. This immense volume of data, though eventually removed, is intended to train their video AI model to perform complex tasks that require a deep understanding of visual content.
Applications of the Cosmos Project

The applications of the Cosmos project are vast. Nvidia aims to use this technology for various purposes. This includes improving video game graphics and enhancing virtual reality experiences. They also aim to develop more sophisticated AI systems. These systems can interact with visual content in a more human-like manner. With Nvidia’s “Video Scraping” removed, the focus shifts to leveraging the Cosmos project. This shift aims to drive innovation in key areas, ensuring immersive and lifelike experiences across digital platforms.
Employee Concerns and Management’s Response
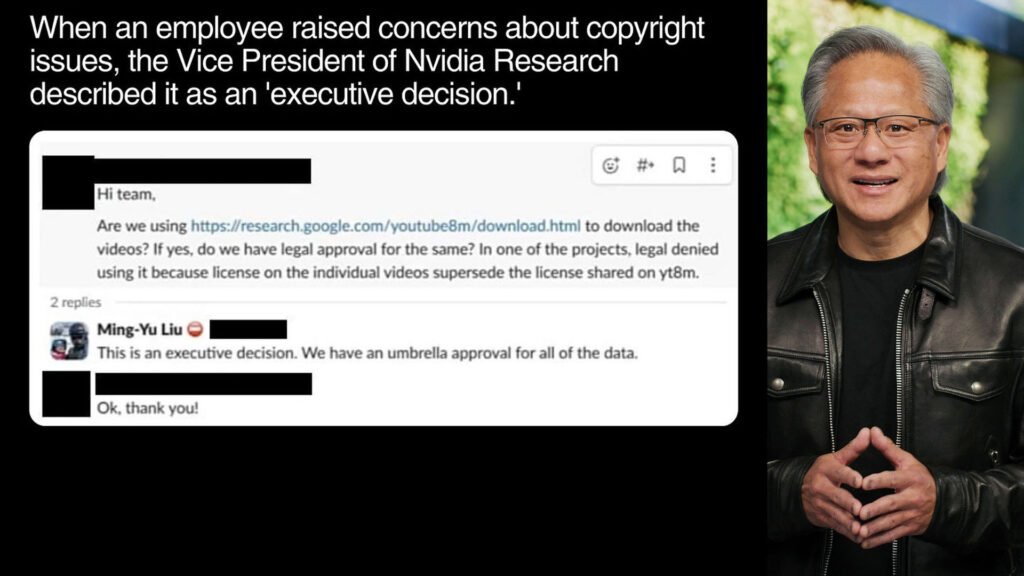
Within Nvidia, employees have raised concerns about the legality and ethics of scraping a large amount of video content. In response, management has assured them that executives approved Nvidia’s Video Scraping practice at the highest levels, implying that the company believes it is on solid legal ground.
Copyright Issues and Fair Use Argument
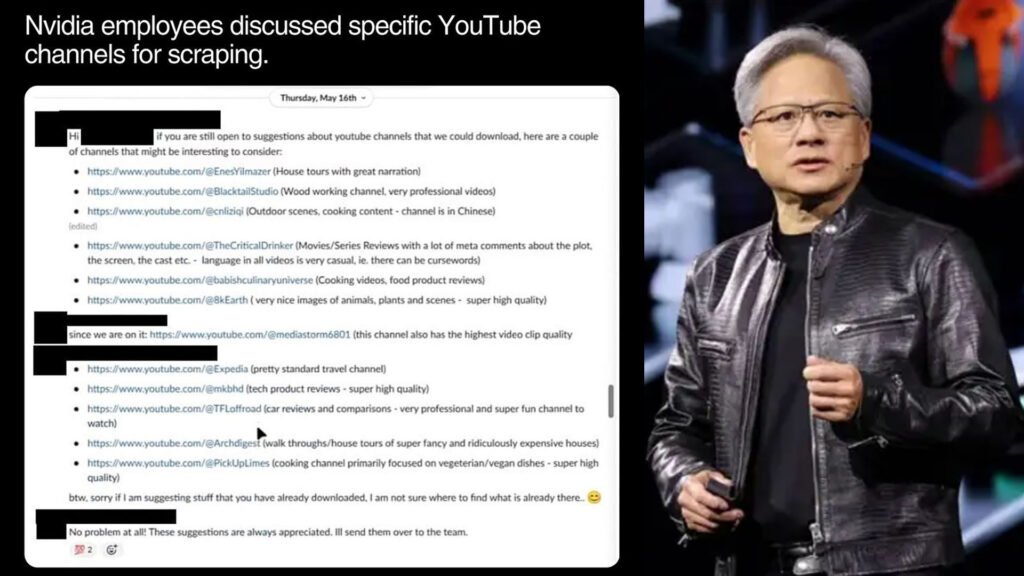
The primary legal concern regarding Nvidia’s practices, particularly Nvidia’s video scraping, is copyright infringement. Nvidia maintains that its actions comply with copyright law, arguing that using copyrighted material for AI training may be considered “fair use.” This legal doctrine allows limited use of copyrighted material without permission under certain circumstances. However, Nvidia’s video scraping practices have raised significant debates, with some arguing for their removal due to potential overreach in copyright boundaries.
Google’s Response to Nvidia’s Practices

Google, which owns YouTube, has expressed concerns about Nvidia’s practices. Google has stated that Nvidia’s video scraping, which involves using YouTube content for AI training, violates its terms of service, highlighting the potential legal battle that could arise from these activities.
Netflix’s Stance on the Matter
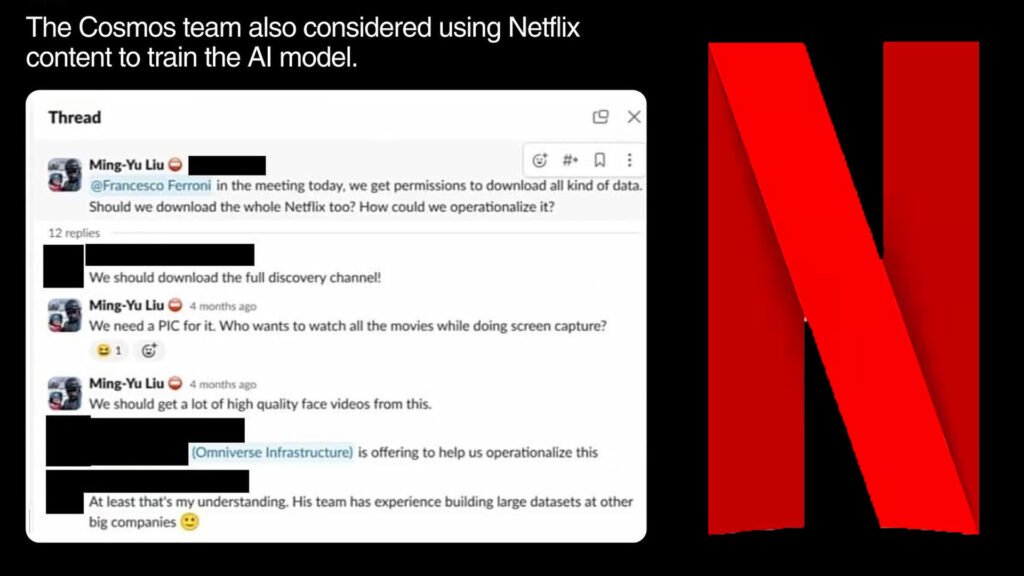
Netflix has also voiced its disapproval of Nvidia’s video scraping, with a spokesperson confirming that there is no agreement for Nvidia to use their content. This stance further complicates Nvidia’s position and raises questions about the legality of their data collection methods. The removal of Nvidia’s video scraping practices from their toolkit now casts a spotlight on the contentious nature of these methods.
Legal Implications and Potential Consequences

The legal implications of Nvidia’s video scraping practices are significant. If found to be in violation of copyright laws, Nvidia could face substantial fines, legal fees, and damage to its reputation. The ongoing debate about fair use in the context of AI training adds another layer of complexity to this issue.
Public Reaction and Media Coverage

The public reaction to Nvidia’s practices has been mixed. While some people see the potential benefits of advanced AI models, others are concerned about the ethical and legal ramifications, especially following the removal of Nvidia’s controversial video scraping methods. Media coverage has been extensive, with many outlets highlighting the controversy and its implications for the future of AI technology.
Ethical Considerations in AI Training

Beyond the legal issues, there are significant ethical considerations surrounding Nvidia’s video scraping practices. The use of scraped content without explicit permission raises questions about the rights of content creators. It also highlights the potential misuse of their work. This debate underscores the need for clear guidelines and regulations in AI. As scrutiny increases, practices may deviate from accepted norms.
Future of AI Video Training Models

Despite the controversy, the future of AI video training models looks promising. As technology advances, it’s likely that new methods and regulations will emerge to address these concerns. With Nvidia’s Video Scraping removed from the equation, Nvidia’s Cosmos project, if successful, could pave the way for groundbreaking developments in AI and video content analysis.
Nvidia’s ambitious “Cosmos” project has brought to light significant issues regarding the use of online video content for AI training. While the potential benefits are immense, the legal and ethical challenges cannot be ignored. As the debate continues, it’s crucial to find a balance that allows for technological advancement while respecting the rights of content creators.
FAQs
1. What is the “Cosmos” project?
The “Cosmos” project is Nvidia’s initiative to create a video foundational model capable of simulating light transport, physics, and intelligence for various applications.
2. What tool does Nvidia use for video scraping?
Nvidia uses an open-source tool called yt-dlp to download video content from platforms like YouTube and Netflix.
3. What are the legal concerns surrounding Nvidia’s practices?
The primary legal concern is copyright infringement. Nvidia argues that its practices fall under fair use, but this is contested by platforms like Google and Netflix.
4. How much video content does Nvidia collect daily?
Nvidia reportedly downloads 80 years’ worth of video content every day to train its AI models.
5. What are the potential applications of the Cosmos project?
Potential applications include improving video game graphics, enhancing virtual reality experiences, and developing more sophisticated AI systems.
Join the Conversation
As Nvidia’s video scraping practices continue to spark debate, we want to hear from you. What are your thoughts on the legal and ethical implications of Nvidia’s ambitious “Cosmos” project? Do you think using vast amounts of video content without explicit permission is justified for the advancement of AI technology, or do you believe it infringes on the rights of content creators?
Share your opinions, questions, and insights in the comments below. Let’s discuss the future of AI, copyright laws, and how companies like Nvidia should navigate these complex issues. Join the conversation and let your voice be heard!







